JX的博客
假如生活欺骗了你,不要悲伤,不要哭泣。
假如生活欺骗了你,不要悲伤,不要哭泣。
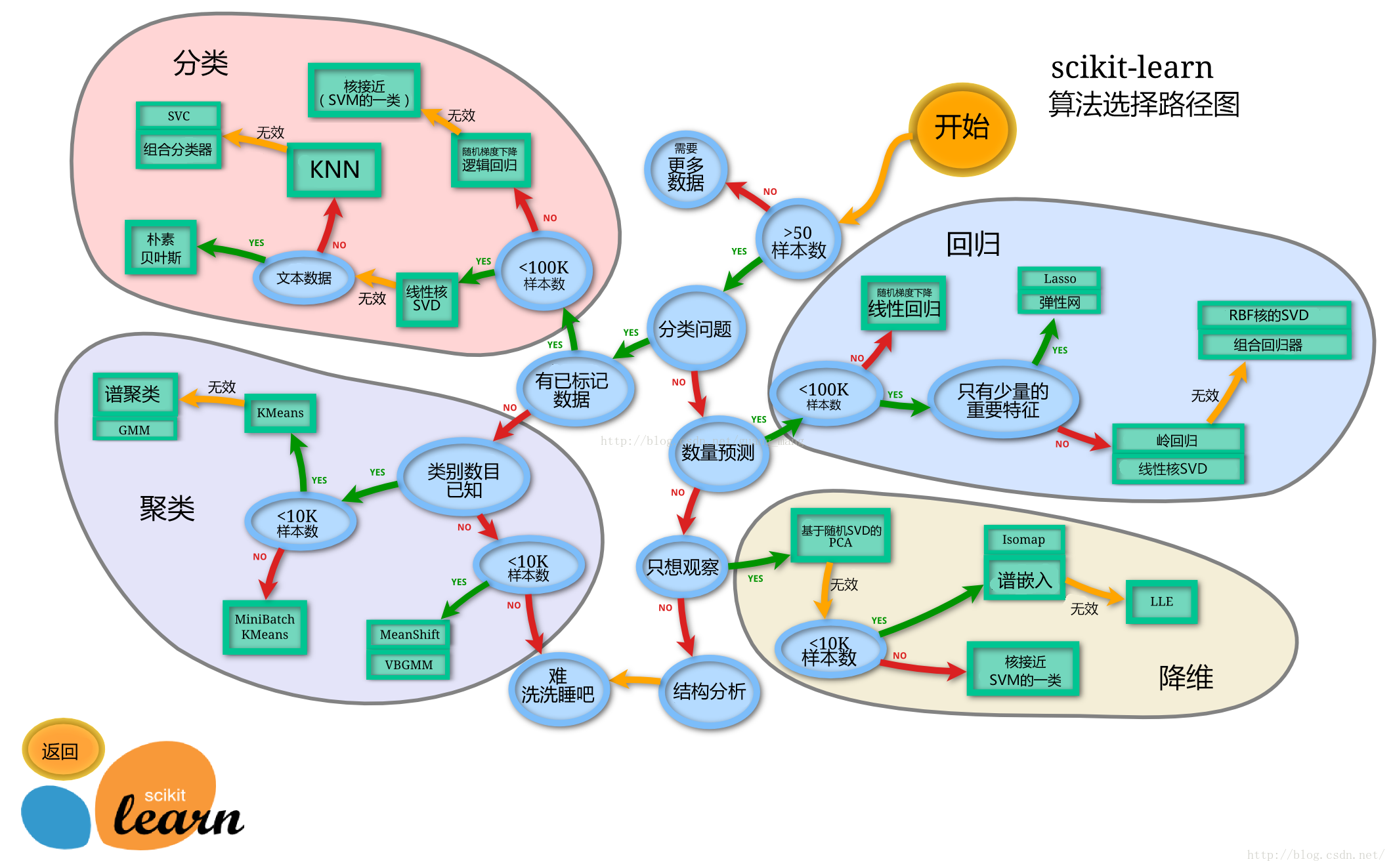
- 常见机器学习算法名单 这里是一个常用的机器学习算法名单。这些算法几乎可以用在所有的数据问题上:
- 线性回归
- 逻辑回归
- 决策树
- SVM
- 朴素贝叶斯
- K最近邻算法
- K均值算法
- 随机森林算法
- 降维算法
- Gradient Boost 和 Adaboost 算法
这里使用py中的sklearn库实现,如何对问题选用合适的模型可以参考下图
线性回归通常用于根据连续变量估计实际数值(房价、呼叫次数、总销售额等)。我们通过拟合最佳直线来建立自变量和因变量的关系。这条最佳直线叫做回归线,结果是所有属性的线性组合。 理解线性回归的最好办法是回顾一下童年。假设在不问对方体重的情况下,让一个五年级的孩子按体重从轻到重的顺序对班上的同学排序,你觉得这个孩子会怎么做?他(她)很可能会目测人们的身高和体型,综合这些可见的参数来排列他们。这是现实生活中使用线性回归的例子。实际上,这个孩子发现了身高和体型与体重有一定的关系, 线性回归的两种主要类型是一元线性回归和多元线性回归。一元线性回归的特点是只有一个自变量。多元线性回归的特点正如其名,存在多个自变量。找最佳拟合直线的时候,你可以拟合到多项或者曲线回归。这些就被叫做多项或曲线回归。
Python 实现
from sklearn import linear_model
#Load Train and Test datasets
x_train=input_variables_values_training_datasets
y_train=target_variables_values_training_datasets
x_test=input_variables_values_test_datasets
# Create linear regression object
linear = linear_model.LinearRegression()
# Train the model using the training sets and check score
linear.fit(x_train, y_train)
linear.score(x_train, y_train)
#Equation coefficient and Intercept
print('Coefficient: n', linear.coef_)
print('Intercept: n', linear.intercept_)
#Predict Output
predicted= linear.predict(x_test)
是一个分类算法而不是一个回归算法。该算法可根据已知的一系列因变量估计离散数值[0,1]。简单来说,它通过将数据拟合进一个逻辑函数来预估一个事件出现的概率。因此,它也被叫做逻辑回归。因为它预估的是概率,所以它的输出值大小在 0 和 1 之间(正如所预计的一样)。
让我们再次通过一个简单的例子来理解这个算法。 假设你的朋友让你解开一个谜题。这只会有两个结果:你解开了或是你没有解开。想象你要解答很多道题来找出你所擅长的主题。这个研究的结果就会像是这样:假设题目是一道十年级的三角函数题,你有 70%的可能会解开这道题。然而,若题目是个五年级的历史题,你只有30%的可能性回答正确。这就是逻辑回归能提供给你的信息。
从数学上看,就是在线性组合的输出上套一个sigma函数或者脚logistic函数,使得输出在(0,1)内。
Python 实现
#Import Library
from sklearn.linear_model import LogisticRegression
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create logistic regression object
model = LogisticRegression()
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Equation coefficient and Intercept
print('Coefficient: n', model.coef_)
print('Intercept: n', model.intercept_)
#Predict Output
predicted= model.predict(x_test)
这个监督式学习算法通常被用于分类问题。令人惊奇的是,它同时适用于分类变量和连续因变量。在这个算法中,我们将总体分成两个或更多的同类群。这是根据最重要的属性或者自变量来分成尽可能不同的组别。挑选最终要的属性是通过分析每个属性的熵增益来挑选的,简单的说就是挑选能能把数据集分的最有秩序的那个属性就是本次挑选的最重要的属性,每次挑选最重要的属性,得到一系列的判断标准,层层筛选。
Python 实现
#Import Library
#Import other necessary libraries like pandas, numpy...
from sklearn import tree
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create tree object
model = tree.DecisionTreeClassifier(criterion='gini') # for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini
# model = tree.DecisionTreeRegressor() for regression
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
这是一种分类方法。在这个算法中,我们将每个数据在N维空间中用点标出(N是你所有的特征总数),每个特征的值是一个坐标的值。
举个例子,如果我们只有身高和头发长度两个特征,我们会在二维空间中标出这两个变量,每个点有两个坐标(这些坐标叫做支持向量)。我们能找到将两组不同数据分开的一条直线。两个分组中距离最近的两个点到这条线的距离同时最优化。
类似在N维空间通过N-1维度的面分开N维中各个点,找到这个超平面的算法就是SVM
Python 实现
#Import Library
from sklearn import svm
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc() # there is various option associated with it, this is simple for classification. You can refer link, for mo# re detail.
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
在预示变量间相互独立的前提下,根据贝叶斯定理可以得到朴素贝叶斯这个分类方法。用更简单的话来说,一个朴素贝叶斯分类器假设一个分类的特性与该分类的其它特性不相关。举个例子,如果一个水果又圆又红,并且直径大约是 3 英寸,那么这个水果可能会是苹果。即便这些特性互相依赖,或者依赖于别的特性的存在,朴素贝叶斯分类器还是会假设这些特性分别独立地暗示这个水果是个苹果。
朴素贝叶斯模型易于建造,且对于大型数据集非常有用。虽然简单,但是朴素贝叶斯的表现却超越了非常复杂的分类方法。
Python 实现
#Import Library
from sklearn.naive_bayes import GaussianNB
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object model = GaussianNB() # there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
该算法可用于分类问题和回归问题。然而,在业界内,K–最近邻算法更常用于分类问题。K – 最近邻算法是一个简单的算法。它储存所有的案例,通过周围k个案例中的大多数情况划分新的案例。根据一个距离函数,新案例会被分配到它的 K 个近邻中最普遍的类别中去。
这些距离函数可以是欧式距离、曼哈顿距离、明式距离或者是汉明距离。前三个距离函数用于连续函数,第四个函数(汉明函数)则被用于分类变量。如果 K=1,新案例就直接被分到离其最近的案例所属的类别中。有时候,使用 KNN 建模时,选择 K 的取值是一个挑战。
注
在选择使用 KNN 之前,你需要考虑的事情:
- KNN 的计算成本很高。
- 变量应该先标准化(normalized),不然会被更高范围的变量偏倚。
- 在使用KNN之前,要在野值去除和噪音去除等前期处理多花功夫。
Python 实现
#Import Library
from sklearn.neighbors import KNeighborsClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create KNeighbors classifier object model
KNeighborsClassifier(n_neighbors=6) # default value for n_neighbors is 5
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
K – 均值算法是一种非监督式学习算法,它能解决聚类问题。使用 K – 均值算法来将一个数据归入一定数量的集群(假设有 k 个集群)的过程是简单的。一个集群内的数据点是均匀齐次的,并且异于别的集群。
Python 实现
#Import Library
from sklearn.cluster import KMeans
#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset
# Create KNeighbors classifier object model
k_means = KMeans(n_clusters=3, random_state=0)
# Train the model using the training sets and check score
model.fit(X)
#Predict Output
predicted= model.predict(x_test)
随机森林是表示决策树总体的一个专有名词。在随机森林算法中,我们有一系列的决策树(因此又名“森林”)。为了根据一个新对象的属性将其分类,每一个决策树有一个分类,称之为这个决策树“投票”给该分类。这个森林选择获得森林里(在所有树中)获得票数最多的分类。
Python 实现
#Import Library
from sklearn.ensemble import RandomForestClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Random Forest object
model= RandomForestClassifier()
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
在过去的 4 到 5 年里,在每一个可能的阶段,信息捕捉都呈指数增长。公司、政府机构、研究组织在应对着新资源以外,还捕捉详尽的信息。
举个例子:电子商务公司更详细地捕捉关于顾客的资料:个人信息、网络浏览记录、他们的喜恶、购买记录、反馈以及别的许多信息,比你身边的杂货店售货员更加关注你。
作为一个数据科学家,我们提供的数据包含许多特点。这听起来给建立一个经得起考研的模型提供了很好材料,但有一个挑战:如何从 1000 或者 2000 里分辨出最重要的变量呢?在这种情况下,降维算法和别的一些算法(比如决策树、随机森林、PCA(主成分分析)、因子分析)帮助我们根据相关矩阵,缺失的值的比例和别的要素来找出这些重要变量。
Python 实现
#Import Library
from sklearn import decomposition
#Assumed you have training and test data set as train and test
# Create PCA obeject pca= decomposition.PCA(n_components=k) #default value of k =min(n_sample, n_features)
# For Factor analysis
#fa= decomposition.FactorAnalysis()
# Reduced the dimension of training dataset using PCA
train_reduced = pca.fit_transform(train)
#Reduced the dimension of test dataset
test_reduced = pca.transform(test)
#For more detail on this, please refer this link.
当我们要处理很多数据来做一个有高预测能力的预测时,我们会用到 GBM 和 AdaBoost 这两种 boosting 算法。boosting 算法是一种集成学习算法。它结合了建立在多个基础估计值基础上的预测结果,来增进单个估计值的可靠程度。这些 boosting 算法通常在数据科学比赛如 Kaggl、AV Hackathon、CrowdAnalytix 中很有效。
Python 实现
#Import Library
from sklearn.ensemble import GradientBoostingClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Gradient Boosting Classifier object
model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
- 瀑布模型
- 优点:
- 降低软件开发的复杂程度,提高软件开发过程的透明性,提高软件开发过程的可管理性
- 推迟软件实现,强调在软件实现前必须进行分析和设计工作
- 以项目的阶段评审和文档控制为手段有效地对整个开发过程进行指导,保证了阶段之间的正确衔接,能够及时发现并纠正开发过程中存在的缺陷,从而能够使产品达到预期的质量要求
- 缺点:
- 强调过程活动的线性顺序
- 缺乏灵活性,特别是无法解决软件需求不明确或不准确的问题
- 风险控制能力较弱
- 瀑布模型中的软件活动是文档驱动的,当阶段之间规定过多的文档时,会极大地增加系统的工作量;而且当管理人员以文档的完成情况来评估项目完成进度时,往往会产生错误的结论。
- 增量模型
- 优点:
- 增强客户对系统的信心
- 降低系统失败风险
- 提高系统可靠性
- 提高系统的稳定性和可维护性
- 缺点:
- 增量粒度难以选择
- 确定所有的基本业务服务比较困难
- 螺旋模型(含原型方法)
- 优点:
- 设计上的灵活性,可以在项目的各个阶段进行变更
- 以小的分段来构建大型系统,使成本计算变得简单容易
- 客户始终参与每个阶段的开发,保证了项目不偏离正确方向以及项目的可控性
- 随着项目推进,客户始终掌握项目的最新信息 , 从而客户能够和管理层有效地交互
- 缺点:
- 采用螺旋模型需要具有相当丰富的风险评估经验和专门知识,在风险较大的项目开发中,如果未能及时标识风险,势必造成重大损失
- 过多的迭代次数会增加开发成本,延迟提交时间
- UP的三大特点:
- 软件开发是一个叠代过程(体现风险驱动的开发)
- 软件开发是由用例驱动的(体系那用户驱动的开发)
- 软件开发是以构架设计为中心的(体现风险驱动的开发)
- 划分准则是每阶段的目标以及产出
- 关键的里程碑:
- 初始阶段:生命周期的目标里程碑,包括一些重 要的文档,如:项目构想 (vision)、原始用例模型、原始业务风 险评估、一个或者多个原型、原始业务案例等。需要对这些文 档进行评审,以确定正确理解用例需求、项目风险评估合理、 阶段计划可行等。
- 细化阶段:生命周期的结构里程碑,包括风险分析文档、软件体系结构基线、项目计划、可执行的进 化原型、初始版本的用户手册等。通过评审确定软件体系结构 已经稳定、高风险的业务需求和技术机制已经解决、修订的项 目计划可行等。
- 构建阶段:初始运作能力里程碑,包括可以运行的软件产品、用户手册等,它决定了产品是否可以 在测试环境中进行部署。此刻,要确定软件、环境、用户是否 可以开始系统的运行。
- 交付阶段:产品发布里程碑,此时,要确定最终 目标是否实现,是否应该开始产品下一个版本的另一个开发周 期。在一些情况下这个里程碑可能与下一个周期的初始阶段的 相重合。
- 工期是在合同里面确定好的,项目的每一个阶段都有规定的完成时间,不能随意更改。而客户在合同中也规定好了项目的验收条件,质量也是不由团队控制的。范围/内容是由团队控制的,因为只有由团队来控制,项目才能够顺利完成。
- RUP的每个阶段可以进一步被分解为迭代过程。迭代过程是导致可执行产品版本(内部和外部)的完整开发循环,是最终产品的一个子集,从一个迭代过程到另一个迭代过程递增式增长形成最终的系统。
使用截图工具(png格式输出),展现你团队的任务 Kanban,请注意以下要求
- 每个人的任务是明确的。即一周后可以看到具体成果
- 每个人的任务是1-2项。
- 至少包含一个团队活动任务
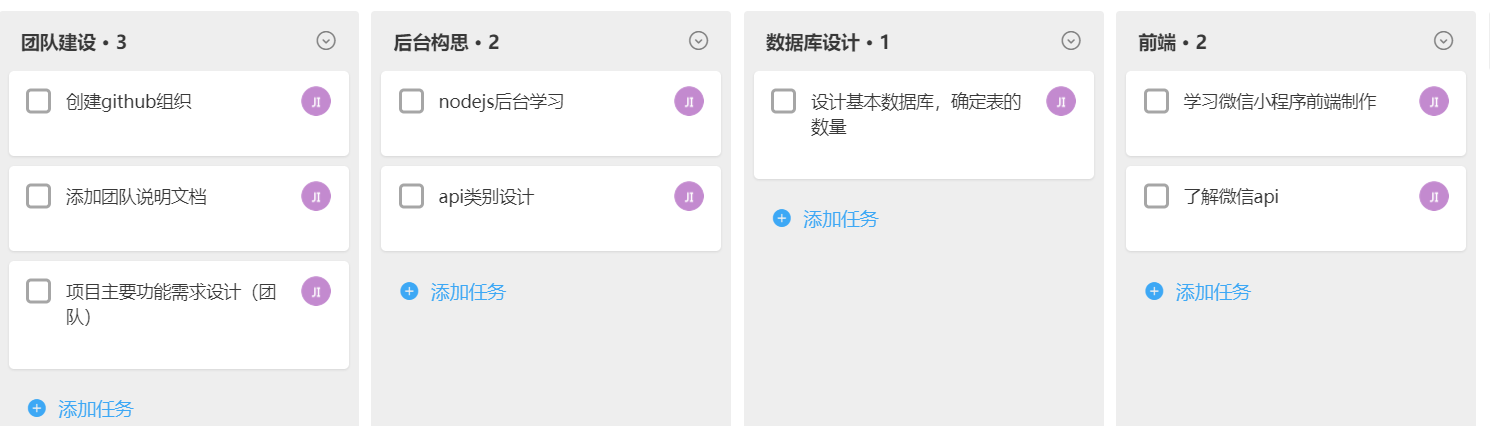
3、deadline 下周四,24点前!
March 21 , 2018 SoftwareEngineering 阅读全文
代码
#include "CImg/CImg.h"
using namespace cimg_library;
void showbmp()
{
CImg<unsigned char> image;
image.load_bmp("1.bmp");
image.display();
}
int main() {
showbmp();
return 0;
}
解释:
编译需要加参数 -O2 -lgdi32 表示优化第二级别 -lgdi32是windows的一个动态库(暂时不知道作用)
代码
void changeColor() {
CImg<unsigned char> img("t.bmp");
cimg_forXY(img, x, y) {
if(img(x,y,0) == 255 && img(x,y,1) == 255 && img(x,y,2) == 255) {
img(x,y,0) = 255;
img(x,y,1) = 0;
img(x,y,2) = 0;
}
else if(img(x,y,0) == 0 && img(x,y,1) == 0 && img(x,y,2) == 0) {
img(x,y,0) = 0;
img(x,y,1) = 255;
img(x,y,2) = 0;
}
}
img.display("2");
}
解释:
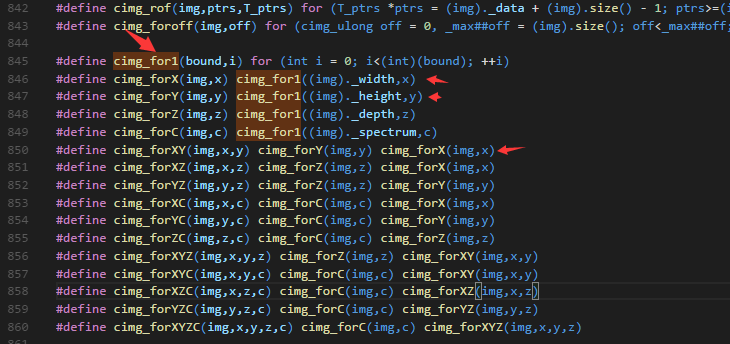
这里使用cimg_forXY方法,是c++的宏用法。 这个宏定义如下:
代码
void yuan3() {
CImg<unsigned char> img("t.bmp");
cimg_forXY(img, x, y) {
double x2 = pow(x-50, 2);
double y2 = pow(y-50, 2);
double distance = sqrt(x2+y2);
// 只需要改变这里的代码就可以完成3或者4
if(distance <= 30.0) {
img(x, y, 0) = 0;
img(x, y, 1) = 0;
img(x, y, 2) = 255;
}
}
img.display("3");
}
半径太小,图像的像素不高,在这个半径中的像素点少所以颗粒感明显,边缘难以平滑。